A robots.txt file is a plain text file that webmasters use to give instructions to web crawlers (also known as robots or spiders) about which pages or sections of their website should or should not be crawled or indexed. It is typically placed in the root directory of a website (e.g., www.example.com/robots.txt).
Key functions of robots.txt:
- Control Crawling: It helps control which parts of a website search engine bots can or cannot visit. This can be useful for preventing the crawling of duplicate content, private data, or areas that aren’t meant to be indexed.
- Prevent Overloading Servers: By limiting how often bots can crawl certain pages or parts of a site,
robots.txtcan reduce the load on the server, especially during heavy bot traffic. - SEO Management: Website owners can use it to guide search engines to focus on important content for indexing while keeping certain pages (like admin pages or internal tools) out of search results.
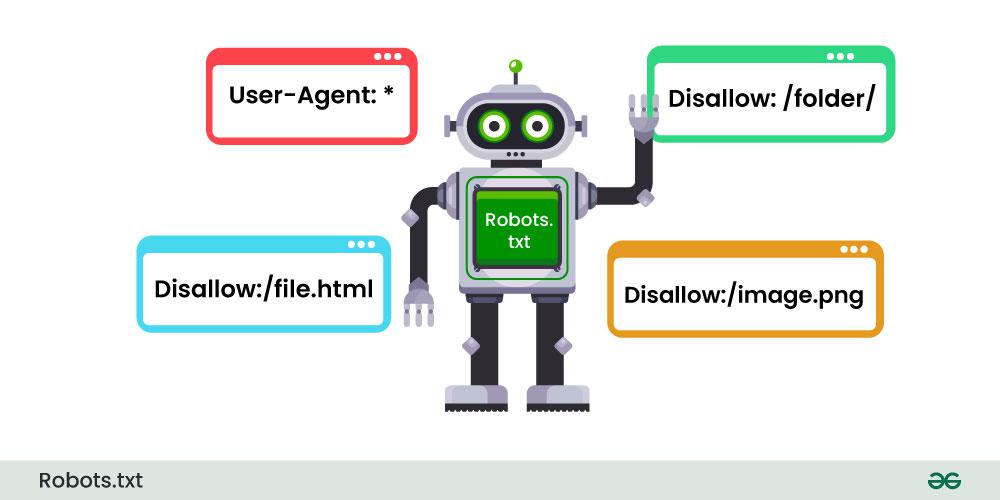
Example of a robots.txt file:
User-agent: Specifies the name of the search engine bot (e.g., Googlebot, Bingbot).Disallow: Tells the bot which paths it should not crawl.Allow: Specifically allows access to certain parts of the site, even if other disallow rules exist.
Limitations:
- Not a Security Feature: It doesn’t prevent bots from accessing disallowed content. It’s a “polite request” to bots, and some bots may ignore the rules.
- Doesn’t Stop Indexing: If a search engine already indexed a page before it was disallowed, the page may still appear in search results, though its content may not be updated.
robots.txt helps in managing web traffic and SEO but isn’t a foolproof method for privacy or security.
A robots.txt file is a standard used by websites to communicate with web crawlers (also known as robots or spiders), giving them guidelines on which pages or sections of the site they should or should not crawl or index. It is a plain text file typically located in the root directory of a website (e.g., www.example.com/robots.txt).
Function of robots.txt:
- Control Crawling: It directs search engine bots (like Googlebot, Bingbot, etc.) on which parts of a website they are allowed or not allowed to crawl. For example, you may want to prevent bots from crawling sensitive or duplicate content, like login pages or admin sections.
- Optimize Server Resources: By limiting how much of the site search engines crawl, webmasters can prevent excessive load on the server, especially when large websites have many pages that don’t need to be indexed.
- SEO Management: It helps site owners guide search engines to focus on important content that should be indexed, while avoiding indexing of irrelevant or sensitive areas of the site.
Example of a robots.txt file:
User-agent: Specifies the search engine or bot (e.g.,Googlebotfor Google,Bingbotfor Bing).Disallow: Tells the bot not to crawl the specified directory or page.Allow: Explicitly allows crawling of certain pages, even if otherDisallowrules apply.